
在数据爬取与信息抓取的领域里,代理IP的集成和反屏蔽策略优化一直是技术人员关注的核心问题。那么,我们如何在页面抓取中高效地使用代理IP,同时又能实现反屏蔽策略的优化呢?本文将为您揭示其中的秘诀,同时提供实践中的一些干货技巧,助力您的爬虫项目达到全新高度。

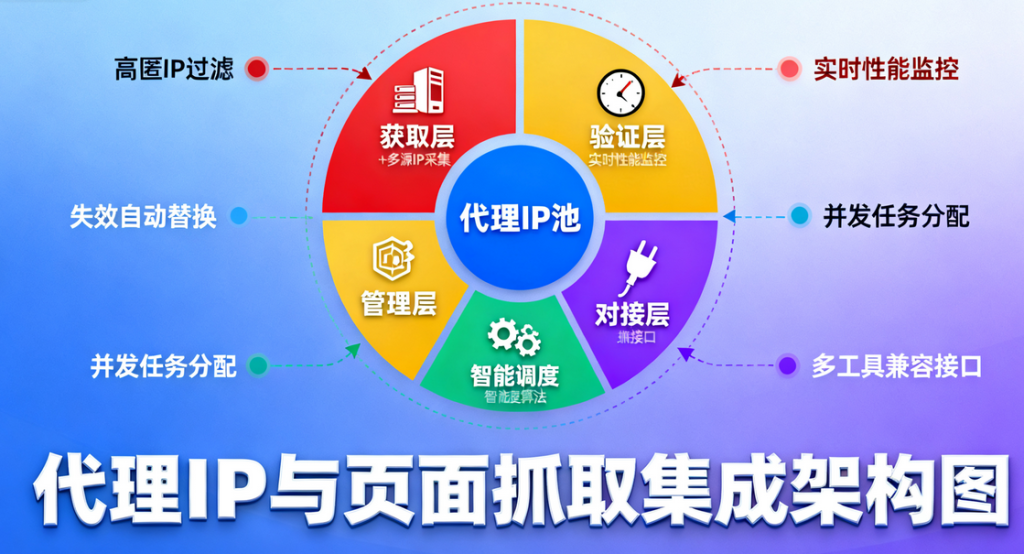
为什么需要代理IP与反屏蔽策略?
如今,越来越多的网站对爬虫行为设置了限制,比如IP封禁、访问速率限制、设备指纹识别等。这些屏蔽机制的存在使得数据抓取的难度显著增加。而代理IP的集成无疑提供了一种有效的解决方法,通过动态切换IP地址,避免固定IP被封禁。同时,结合反屏蔽策略,可以伪装请求,以降低被目标网站检测到的风险。
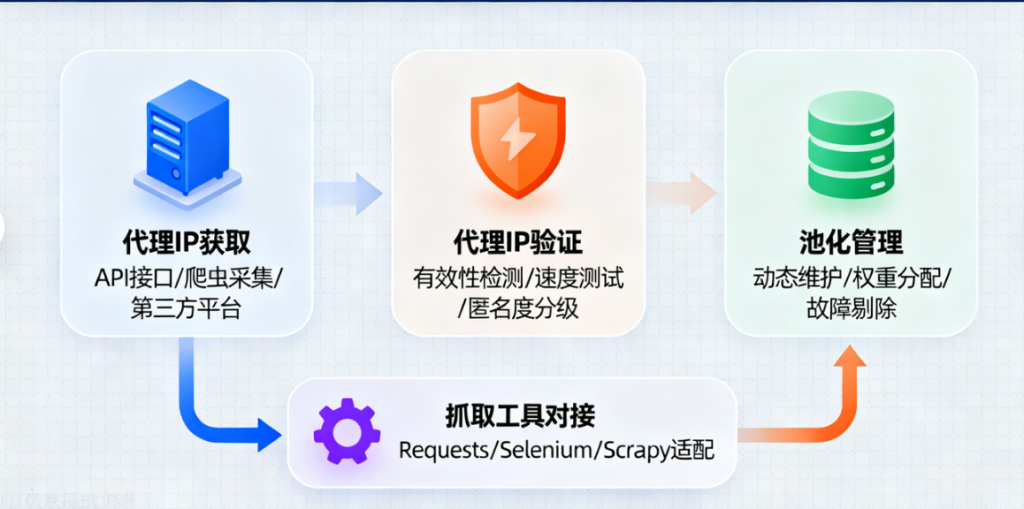
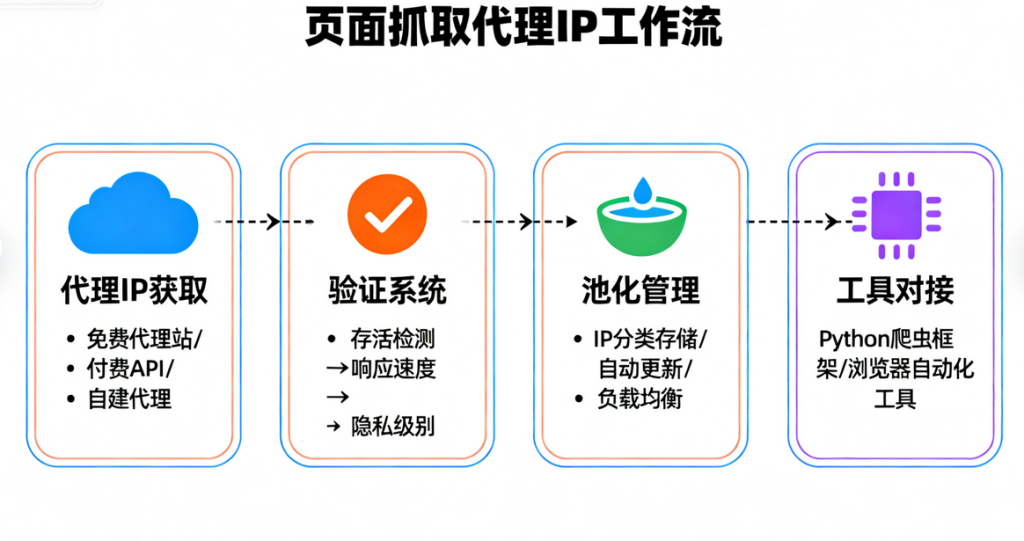
如何集成页面抓取代理IP?
1. 选择合适的代理IP服务商:代理IP的质量直接决定了抓取成功率。选择那些提供高匿名性、高可用性且支持频繁切换的服务商会更符合需求。
2. 实现代理IP的动态切换:在代码层面通过第三方库(如Python的requests或Scrapy等),配置代理池并动态调用。这可以有效避免单个IP的过度使用。
3. 监控代理IP的稳定性:集成代理IP后,需要对使用效果进行实时监控。通过定期检查IP的可用性、延迟和成功率,进一步优化抓取效率。
优化反屏蔽策略的实战技巧
1. 模拟真实用户行为:通过设置随机的请求头(User-Agent、Referer等)以及访问间隔时间,尽量让爬虫的行为接近真实用户。
2. 多设备指纹伪装:结合工具生成不同的设备特征(如浏览器、系统类型),以迷惑目标服务器的指纹识别系统。
3. 分布式抓取:利用分布式爬虫框架(如Scrapy-Cluster)将抓取任务分散到多个节点,进一步降低单点检测风险。
小结
代理IP的集成与反屏蔽策略的优化是爬虫技术中的关键环节。在实践中,选用优质代理IP服务商,同时结合真实用户行为的模拟与多维伪装技术,才能有效突破屏蔽限制,实现高效的页面抓取。
原创文章,作者:余初云,如若转载,请注明出处:https://blog.jidcy.com/ip/gndl/801.html